Emotion recognition using multimodal matchmap fusion and multi-task learning
Abstract - An Overview of Our Research
Recognizing emotions is a demanding task due to the immense intra-class and inter-class variability inherent to this issue. The way different individuals express a single emotion can vary, resulting in many potential interpretations. Also, some emotions resemble each other, thereby adding another layer of complexity.
To tackle this problem, our research investigated the use of multimodal techniques, multi-task learning methods, and deep learning. A matchmap fusion method based on similarity between audio and video modalities was employed for solving the emotion classification issue. Our results depicted that utilizing the fusion method improved classification by 7%, in comparison to the baseline model.
Introduction - Why Emotion Recognition Matters
Emotion recognition opens new frontiers for human-machine interactions, including everything from automatically generating robot responses depending on a user’s mood to estimating a patient’s mental state for prioritized health care.
Our work focused on analyzing a multimodal estimation encompassing several input signals. In a nutshell, we tried to enhance the efficiency of the classifier or regressor by leveraging more than one input signal.
The Experiment - How We Went About It
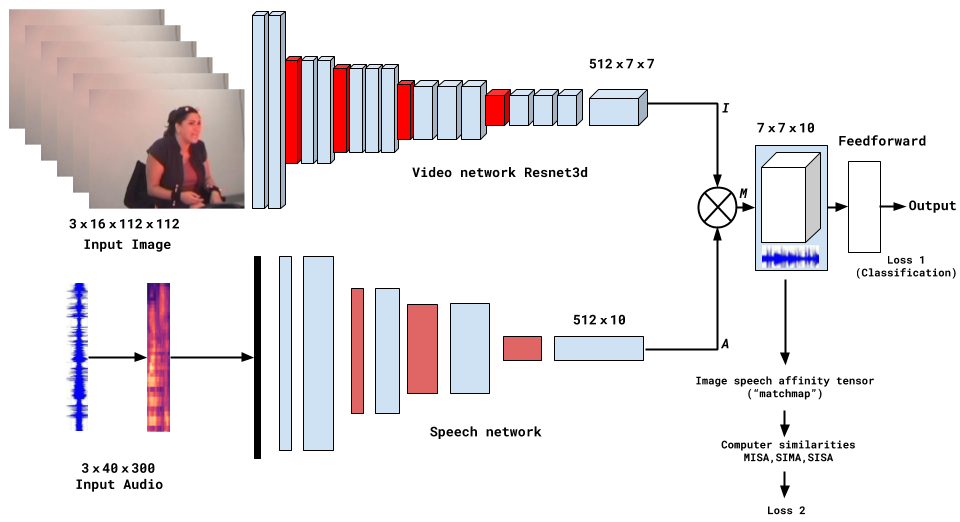
In our experiment, we deployed an architecture that involved using log mel spectrograms as audio features and trained our convolutional network to capture more suitable features for the experiment. We used a Resnet3D architecture for estimating facial expressions from a video sequence.
To merge the attributes from different modalities, we used matchmap, a fusion method based on the similarity between audio and video tensors.
Two loss functions were used: first, a cross-entropy function for classification and second, a loss function based on matchmap tensor. Our experiments were carried out on the Interactive Emotional Dyadic Motion Capture (IEMOCAP) database. The IEMOCAP dataset comprises of five sessions that record ten speakers’ conversations. Each recorded conversation represents different emotional states and is used as training data. Two settings comprise the audio data: scripted and improvised speech. In the scripted setting, speakers are asked to read specific dialogues aloud, while the improvised setting includes spontaneous speech, closely resembling natural conversation. The collected data consists of 10,039 tagged utterances, each with an average duration of 4.5 seconds and a sample rate of 16 kHz.
The Matchmap Fusion Method - A Closer Look
Matchmap fusion is an advanced technique used in multimodal research. The main goal of this fusion is to represent the relationships between different modalities, such as audio and video. This involves creating a tensor that represents the similarity between different audio and video features.
Let’s dive deep into how matchmap fusion works. After feeding video and audio data through their respective deep learning models, we obtain two sets of features - one from each modality. These tensor outputs are transposed and a dot product operation is performed between them, creating a new tensor, referred to as the matchmap tensor.
The idea of a matchmap is to compute a localized similarity between a small region of audio and video modalities. It provides a way of capturing the synergistic relationship between different types of inputs and leveraging the complementary information they provide to solve the problem in hand.
Let’s consider the problem of emotion recognition based on audio and video data. Here, the matchmap fusion can help to create representations that depict an emotion revealed in both audio and video sections. These learned relationships help enhance the distinction between different emotions and deal with the existing intra-class and inter-class variability, thereby improving the classification accuracy.
Depending on the loss function used, various types of similarity functions can be derived from the matchmap tensor. This includes sum image sum audio (SISA), max image sum audio (MISA), and sum image max audio (SIMA), which can be used depending on the requirements of the specific task at hand.
By using a matchmap fusion, we can develop more advanced and accurate classifiers, which can not only utilize the strengths of each modality but can also deal with the inherent difficulties associated with their combination. For example, in the case of emotion recognition, this fusion method is reported to have resulted in improvements in classification accuracy.
Results, in a Nutshell
Our studies indicated that the use of multimodal techniques, deep learning and matchmap fusion considerably improved the process of emotion recognition. The results were also comparable with other leading research in this field.
We demonstrated that a multimodal matchmap fusion method can give better results when one of the unimodal signals is underperforming. This proved that the algorithm allows the mixing of information from each modality, using all or little information that each mode provides improving inter-class results and reducing intra-class variability.
What Lies Ahead - Future Scope
Although we made significant progress, we believe that there is a lot of scope for improvement. We plan to further our research to perfect the emotion estimation results for video sequences from the IEMOCAP database. We are also exploring the integration of recurrent neural network techniques and LSTM networks for long-term dependencies inherent in this problem.
Acknowledgment: We extend our gratitude to the Master of Computer Engineering and the Nucleus Research in Artificial Intelligence and Data Science from the Universidad Católica del Norte for their immense support.